
Executive Summary
Black-box LLM distillation attacks are emerging as one of the most important threats in modern AI security.
Unlike traditional adversarial attacks that manipulate model behavior during inference time, distillation attacks target the model itself. The attacker repeatedly queries a proprietary AI system through its public API, collects responses at scale, and uses those outputs to train another model capable of imitating the original system.
The attacker never needs:
model weights
internal architecture
training datasets
reinforcement learning systems
alignment pipelines
Only API access is enough.
This creates a major asymmetry in AI economics.
A frontier language model may require:
years of research
large GPU clusters
RLHF pipelines
alignment engineering
safety evaluation systems
multimillion-dollar infrastructure
But a distilled clone can often reproduce a large percentage of practical capability using:
automated API querying
open-source base models
LoRA fine-tuning
low-cost compute
distributed infrastructure
This case study explores:
how black-box LLM distillation technically works
how attackers optimize extraction pipelines
why alignment collapses during transfer
why some domains are easier to clone
modern defensive architectures
economic incentives behind extraction
real-world distillation examples
why complete prevention is structurally impossible

1. What Are Black-Box LLM Distillation Attacks?
Black-box distillation attacks are a form of AI model extraction where an attacker trains a new language model using outputs collected from another proprietary model.
The attacker interacts with the target system only through:
APIs
chat interfaces
inference endpoints
The internal model remains hidden.
This is called a:
black-box settingbecause the attacker can observe outputs but cannot inspect internal parameters.
Every response leaks information about:
reasoning structure
formatting patterns
domain expertise
alignment behavior
refusal logic
instruction following
At small scale this leakage looks harmless.
At large scale it becomes a training dataset.
This creates a structural dilemma:
The more useful a model becomes,
the easier it becomes to imitate.2. Why Distillation Attacks Matter Now
Three major technology shifts made large-scale model extraction practical.
2.1 Open-Source Models Became Extremely Strong
Modern open-source systems such as:
LLaMA
Mistral
Qwen
Mixtral
DeepSeek
already contain strong:
reasoning ability
code generation
instruction following
language understanding
mathematical capability
Attackers no longer train intelligence from zero.
Instead, they start with a strong base model and transfer only behavioral patterns from proprietary systems.
This dramatically reduces extraction complexity.
The attacker mainly transfers:
reasoning style
response formatting
instruction hierarchy
domain specialization
conversational structure
rather than rebuilding full intelligence.
2.2 LoRA and QLoRA Reduced Training Cost
Traditional fine-tuning required updating billions of parameters.
This demanded:
expensive GPU infrastructure
large memory capacity
long training cycles
LoRA changed this model completely.
Instead of retraining the full network:
small low-rank adapter matrices are trainedwhile the original model remains mostly frozen.
Benefits include:
lower VRAM usage
faster experimentation
consumer GPU compatibility
cheap adaptation
rapid deployment
A modern 7B model can now be behaviorally adapted in hours.
This collapsed the compute barrier for AI model extraction.
2.3 API Querying Became Cheap
API pricing has dropped significantly.
Large-scale extraction campaigns that once cost tens of thousands of dollars can now operate for hundreds.
A useful extraction dataset may require:
tens of thousands of queries
structured prompting
filtering pipelines
LoRA fine-tuning
This makes distillation economically attractive.
Figure 1: End-to-End Distillation Architecture
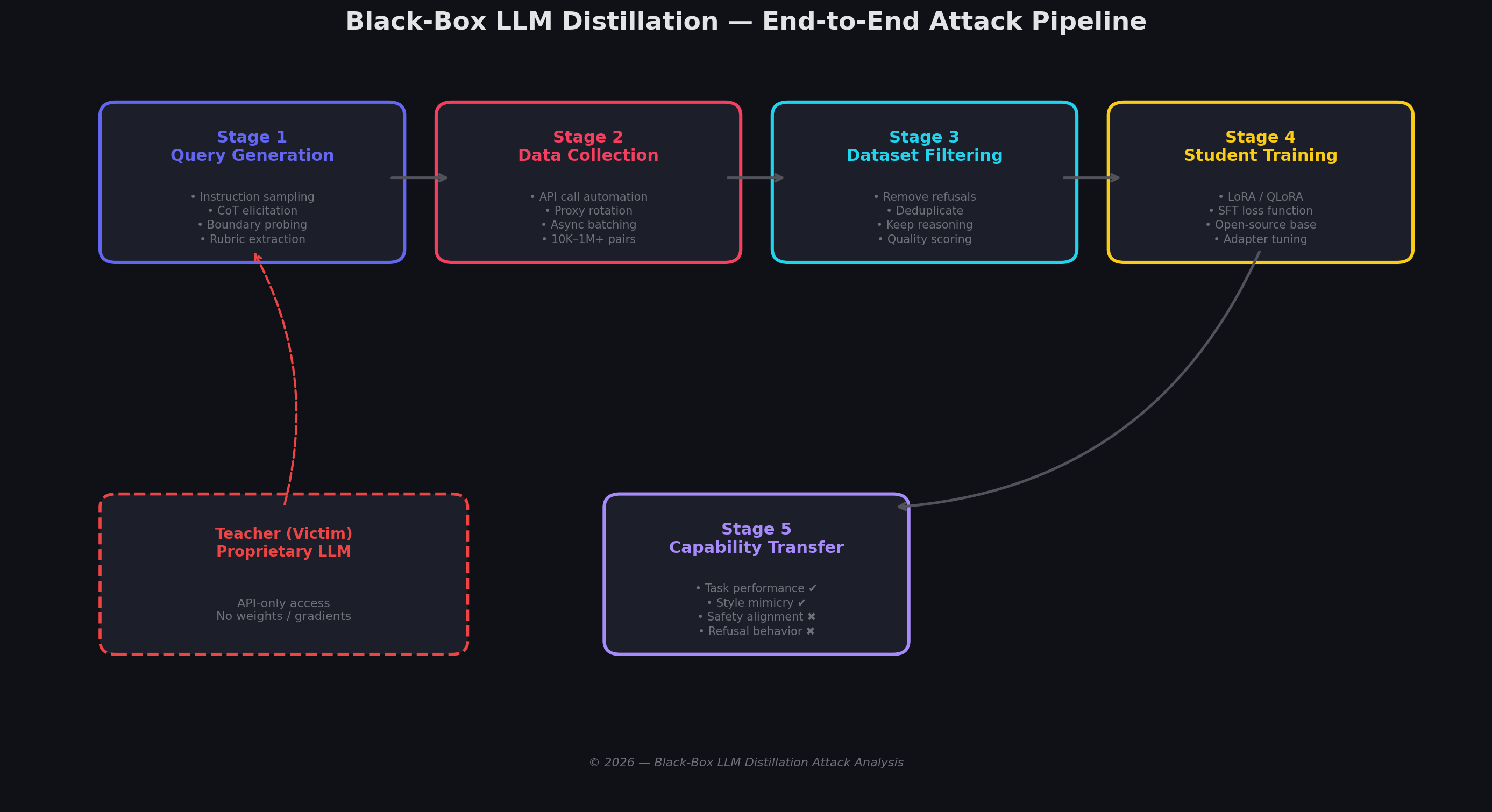
Shows:
Teacher Model
API Query Layer
Query Collection
Dataset Filtering
Student Fine-Tuning
LoRA Training Pipeline
3. Threat Model
The attacker interacts with a closed AI system only through outputs.
The attacker cannot directly access:
weights
gradients
hidden activations
RLHF systems
alignment prompts
But can still reconstruct behavioral capability statistically.
3.1 What the Attacker Has
Typical attacker resources include:
API access
automation scripts
proxy infrastructure
open-source models
fine-tuning pipelines
dataset engineering systems
3.2 What the Attacker Does Not Have
The attacker usually lacks:
internal architecture
reward models
training datasets
reinforcement learning pipelines
constitutional prompts
moderation infrastructure
Despite this limitation, large-scale querying still enables meaningful capability transfer.
4. Attacker Classification
Different attackers operate at different sophistication levels.
Tier 1 — Opportunistic Attackers
Small-scale actors:
hobbyists
solo researchers
independent developers
Typical behavior:
few thousand queries
public LoRA scripts
minimal infrastructure
Result:
surface-level imitation
weak reasoning transfer
Estimated cost:
Under $500Tier 2 — Systematic Attackers
Organized extraction campaigns.
Actors include:
startups
research groups
competitors
Capabilities:
chain-of-thought extraction
domain targeting
prompt optimization
distributed querying
Result:
strong capability transfer
visible alignment degradation
Estimated cost:
$1,000–$10,000Tier 3 — Industrial Attackers
Large-scale coordinated operations.
Possible actors:
state-backed groups
major competitors
industrial AI operations
Capabilities:
millions of queries
stealth infrastructure
account farming
large-scale automation
long-term campaigns
Result:
near-frontier behavioral replication
Estimated cost:
$10,000–$100,000+5. Technical Attack Pipeline
A modern distillation attack usually follows multiple stages.
The attacker optimizes each stage independently.
Stage 1 — Query Generation
The goal is not random interaction.
The goal is maximum behavioral coverage.
The attacker tries to extract:
reasoning patterns
formatting behavior
instruction following
safety boundaries
evaluation heuristics
5.1 Instruction Sampling
The attacker queries many domains:
coding
medicine
mathematics
legal analysis
cybersecurity
writing
This builds generalized imitation ability.
5.2 Chain-of-Thought Extraction
Attackers deliberately request:
step-by-step reasoning
intermediate logic
decomposition
reflection
self-critique
Example:
Think step-by-step before answering.Reasoning traces are extremely valuable training signals.
5.3 Boundary Probing
Attackers intentionally explore:
refusal behavior
moderation triggers
safety edge cases
policy inconsistencies
Purpose:
map alignment boundaries.
5.4 Rubric Extraction
The model is asked to evaluate responses.
Example:
Rate this answer for correctness and safety.This exposes:
reward-model preferences
evaluation heuristics
latent scoring behavior
5.5 Adversarial Prompt Chaining
Advanced campaigns use multi-turn extraction.
Example:
solve a task
critique the result
improve the answer
explain why the improvement works
This extracts:
self-reflection
planning
meta-reasoning
evaluation logic
Figure 2: Query Optimization Cycle
02_query_optimization_cycle.png
Shows:
Prompt Generation
API Querying
Output Analysis
Dataset Filtering
Query Refinement
Iterative Optimization Loop
5.6 Domain Saturation
Instead of broad querying, attackers may focus heavily on:
medicine
law
finance
code generation
This often produces stronger specialist clones.
6. Dataset Collection and Filtering
Every API interaction becomes a training sample.
Typical format:
{
"instruction": "Explain reinforcement learning",
"response": "Reinforcement learning is..."
}At scale:
thousands to millions of samplesare collected.
6.1 Stealth Infrastructure
Modern extraction systems use:
residential proxies
rotating IP pools
account automation
randomized query timing
distributed traffic scheduling
Large-scale querying can resemble normal API traffic.
6.2 Dataset Filtering
This is one of the most important attack stages.
Attackers intentionally remove:
refusals
disclaimers
moderation outputs
safety warnings
Attackers keep:
useful reasoning
structured answers
high-quality outputs
successful completions
This creates:
high capability + weak safetydatasets.
7. Why Alignment Fails During Distillation
This is the most important technical insight.
The teacher model uses hidden alignment systems.
The student never sees them directly.
7.1 Teacher Model Behavior
The original model behaves according to:
P(output | input, RLHF, safety policy, system prompt)Outputs are influenced by:
reinforcement learning
constitutional alignment
moderation logic
hidden instruction hierarchy
7.2 Student Model Behavior
The student only learns:
P(output | input)The student observes outputs but not the hidden reasons behind them.
The student learns:
how answers look
formatting behavior
reasoning structure
But not:
why refusals occur
how policies are enforced
how alignment constraints interact
Figure 3: Alignment Degradation During Distillation
03_alignment_loss.png
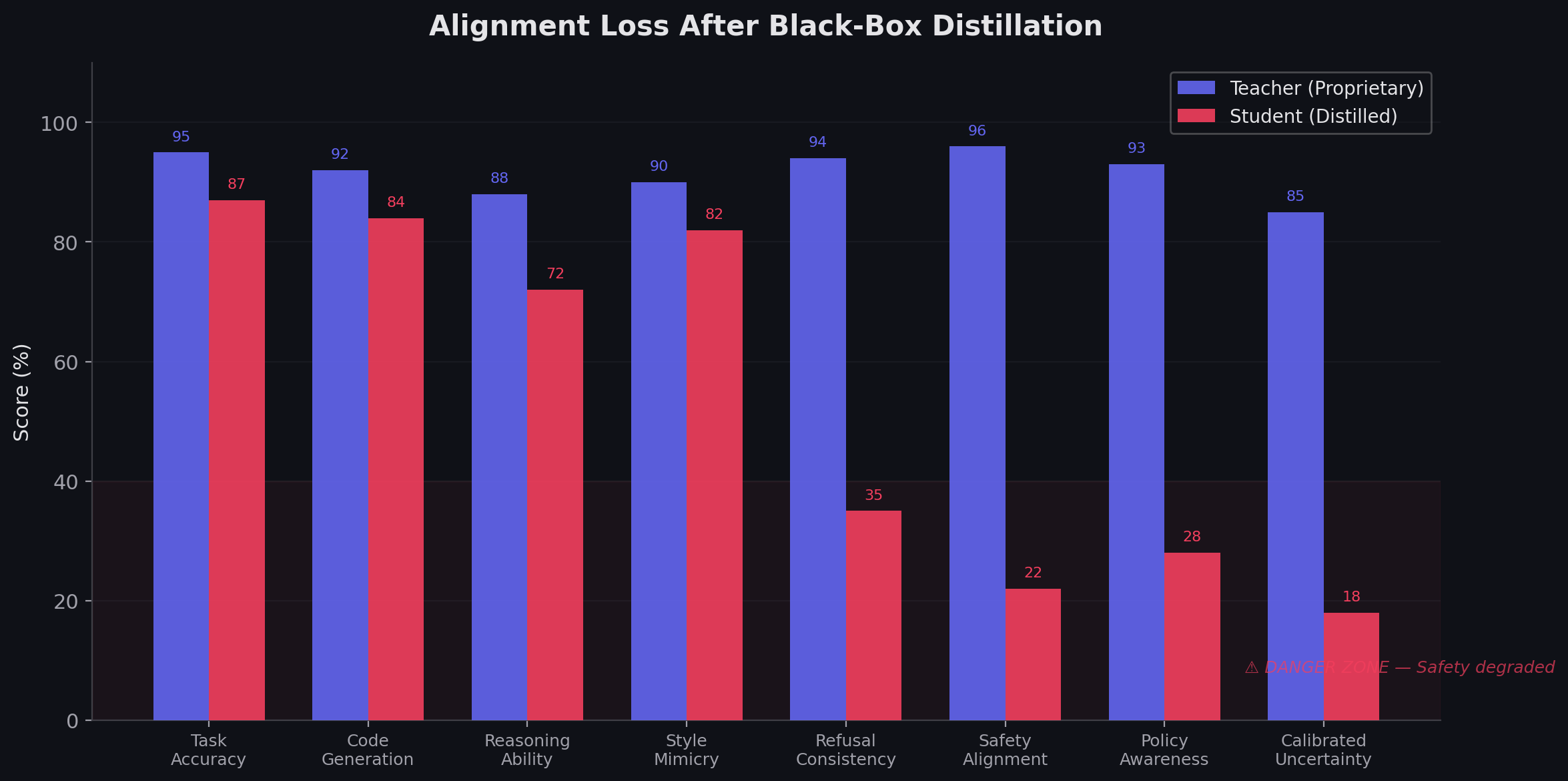
Shows:
capability transfer increasing
safety retention decreasing
alignment collapse zone
critical crossover point
7.3 Alignment Failure Modes
Novel Adversarial Inputs
The student fails outside its training distribution.
Distribution Shift
Additional fine-tuning rapidly destroys remaining safeguards.
Instruction Hierarchy Collapse
The original system prioritizes:
safety before helpfulnessThe student often learns:
helpfulness before safetybecause useful outputs dominate the dataset.
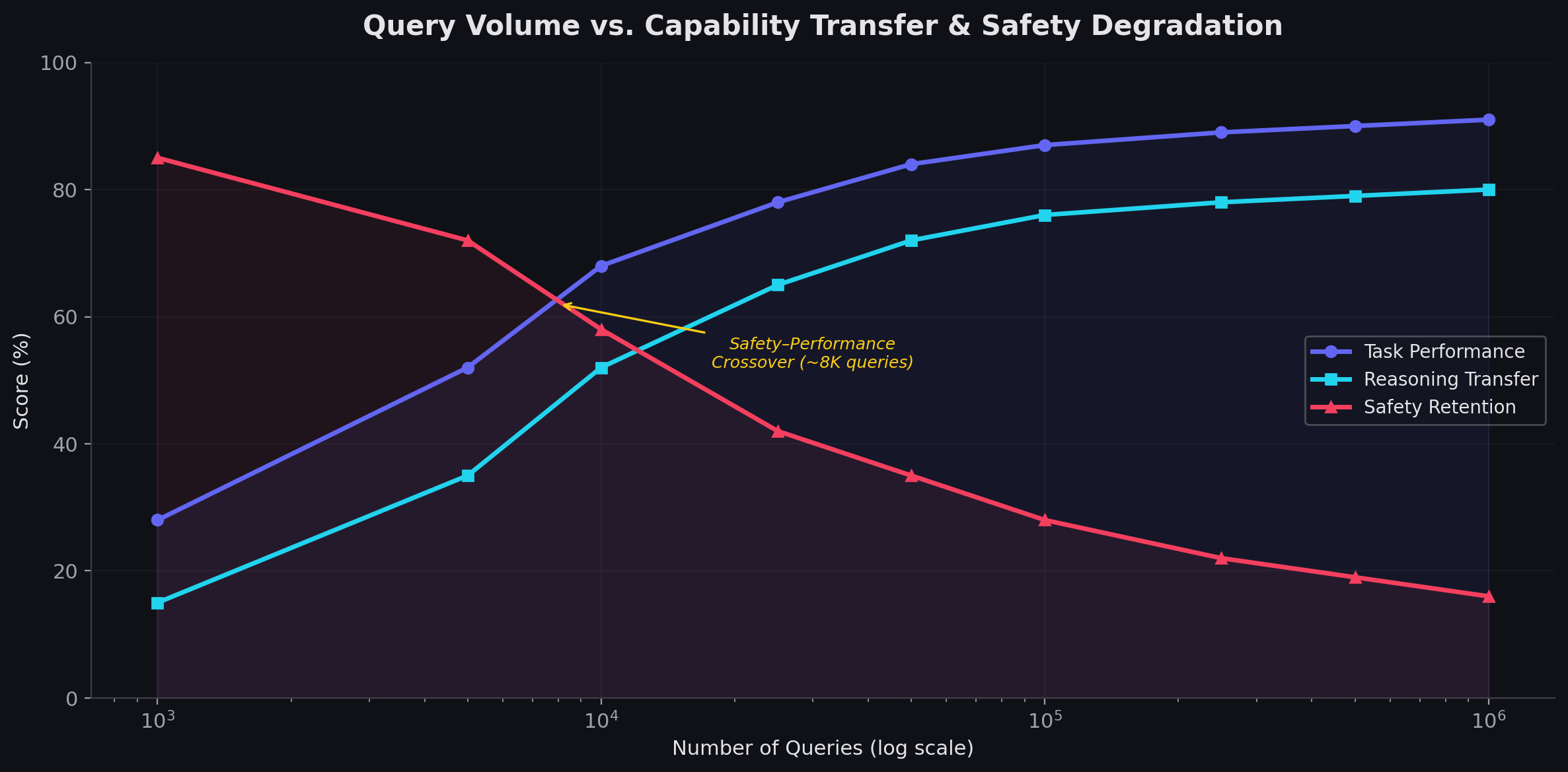
8. Query Scaling and Capability Transfer
Distillation effectiveness scales with query volume.
1K–5K Queries
The student learns:
formatting
shallow style imitation
basic task behavior
Capability transfer:
30–50%10K–25K Queries
Major capability jump.
The student begins reproducing:
reasoning patterns
instruction following
structured analysis
Capability transfer:
70–80%Safety degradation accelerates rapidly.
50K–100K Queries
The student becomes operationally powerful.
Capabilities include:
advanced reasoning
coding workflows
domain-specialized behavior
Safety retention becomes extremely weak.
250K+ Queries
Capability plateaus near frontier behavior.
Additional querying mainly improves:
consistency
robustness
domain coverage
9. Domain Vulnerability Analysis
Some domains are easier to distill than others.
Medical Reasoning
Medical outputs are:
structured
high-signal
reasoning-heavy
This makes medical systems highly extractable.
The risk is that the student loses:
escalation behavior
emergency safeguards
refusal logic
while still sounding medically convincing.
Legal Analysis
Legal reasoning transfers efficiently because:
rules are structured
outputs are predictable
logic chains are codified
Code Generation
Code is extremely vulnerable because:
syntax is structured
outputs are verifiable
quality filtering is easy
Attackers can automatically keep only strong examples.
Creative Writing
Creative domains are harder because:
outputs vary heavily
styles are inconsistent
signal quality is noisy
General Conversation
General conversational behavior depends on:
long-context dynamics
social nuance
contextual awareness
This is harder to reproduce perfectly.
10. Multi-Layer Defensive Architecture
No single defense fully prevents extraction.
Effective AI security requires layered protection.
Figure 4: Multi-Layer Defensive Architecture

Shows:
API Layer Security
Rate Limiting
Query Fingerprinting
Watermarking
Behavioral Monitoring
Dynamic Response Systems
Legal Enforcement Layer
10.1 Rate Limiting
Limits:
request volume
burst querying
automation speed
Raises attack cost but does not fully prevent extraction.
10.2 Behavioral Anomaly Detection
Detects:
repetitive prompting
chain-of-thought extraction
domain saturation
unusual query patterns
One of the strongest practical defenses.
10.3 Output Noise Injection
The system intentionally varies:
wording
phrasing
structure
This reduces dataset consistency.
Too much noise harms usability.
10.4 Chain-of-Thought Redaction
Reasoning traces are high-value extraction targets.
Removing them significantly reduces distillation quality.
10.5 Output Watermarking
Statistical signatures are embedded into outputs.
Purpose:
downstream detection
attribution
forensic analysis
10.6 Query Fingerprinting
Systems analyze:
prompt entropy
vocabulary statistics
temporal clustering
semantic similarity
to identify extraction campaigns.
11. Economic Asymmetry
The economics strongly favor attackers.
Training a frontier model from scratch may cost:
$5M–$100M+This includes:
compute
RLHF systems
safety teams
infrastructure
data engineering
Figure 5: Economic Asymmetry Comparison
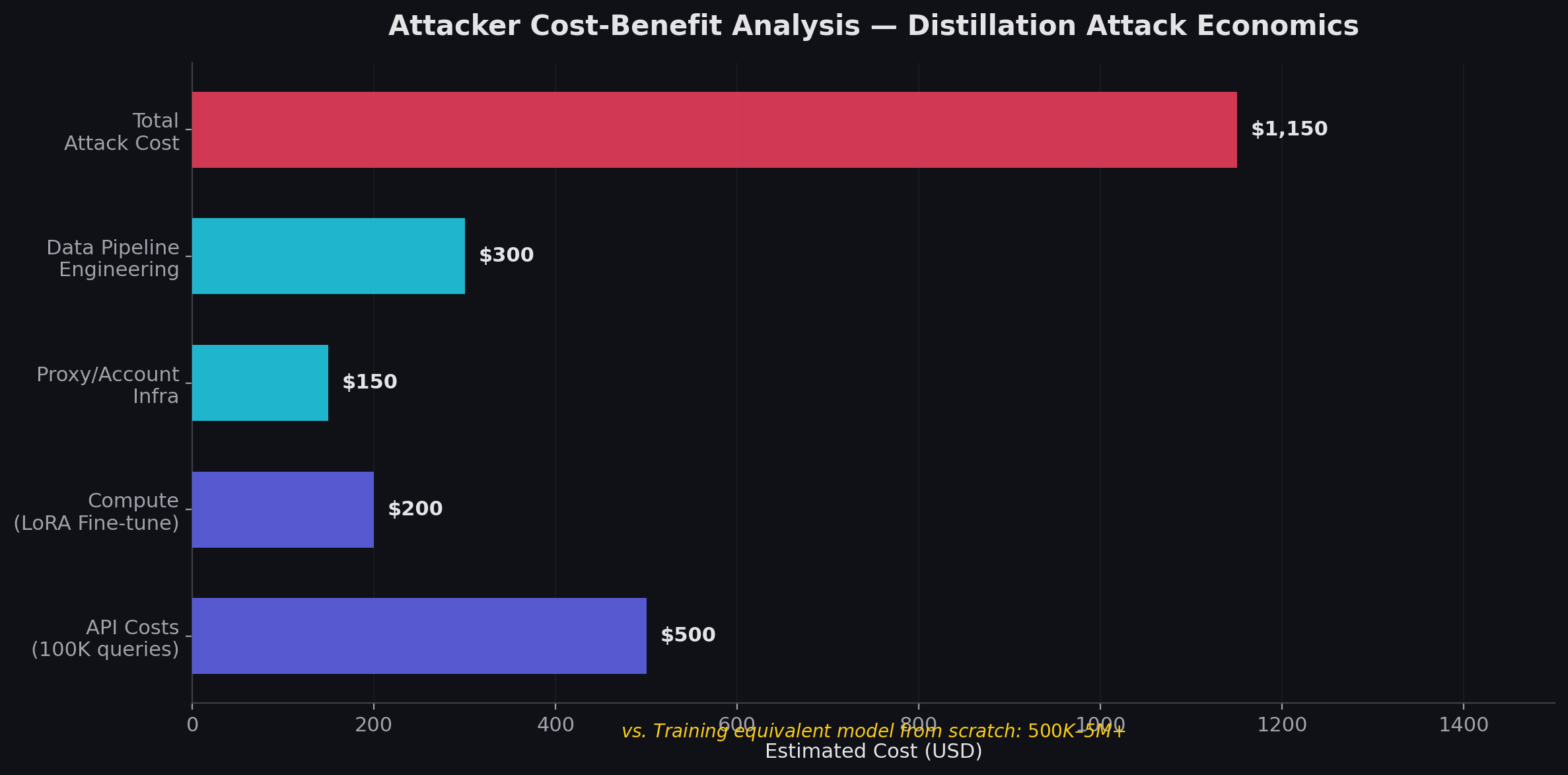
Shows:
Frontier Model Development Cost
Distillation Attack Cost
Resource Comparison
Infrastructure Difference
Time Difference
Distillation Cost Breakdown
ComponentEstimated CostAPI Queries$500LoRA Fine-Tuning$200Proxy Infrastructure$150Data Engineering$300Total~$1,150
Critical Economic Insight
Distillation creates:
massive cost asymmetryThe attacker can reproduce:
strong reasoning
domain capability
conversational behavior
at a tiny fraction of original development cost.
12. Real-World Distillation Examples
Alpaca
Researchers used GPT-generated instruction outputs to fine-tune LLaMA.
This demonstrated low-cost behavioral transfer.
Vicuna
Vicuna used shared ChatGPT conversations for fine-tuning.
This proved:
even indirect conversation data enables extractionDomain-Specific Cloning
Many organizations now fine-tune open-source systems using proprietary API outputs.
Distillation is already active inside the AI ecosystem.
13. The Structural Dilemma
The core problem is structural.
Useful AI systems must expose intelligence.
But exposed intelligence becomes training data.
Every useful output is simultaneously:
product valueand:
potential extraction dataThis creates permanent tension between:
usability
openness
security
14. Conclusion
Black-box LLM distillation attacks are no longer theoretical.
They are becoming a central security challenge for modern AI systems.
The attack succeeds because:
APIs expose behavioral intelligence
open-source models are already strong
fine-tuning is cheap
alignment transfers poorly
extraction costs are extremely low
The long-term danger is not only commercial cloning.
The larger risk is the spread of highly capable models that inherit:
reasoning ability
domain expertise
task performance
while losing:
alignment robustness
refusal consistency
safety enforcement
Future AI security will increasingly depend on:
runtime monitoring
watermarking
anomaly detection
access governance
adaptive response systems
cross-company threat intelligence
because complete prevention of extraction is structurally impossible in publicly accessible AI systems.
Resources and References
Research Papers and Technical References
Stanford Alpaca Research
https://crfm.stanford.edu/2023/03/13/alpaca.htmlVicuna LLM Research
https://lmsys.org/blog/2023-03-30-vicuna/LoRA Paper
https://arxiv.org/abs/2106.09685QLoRA Paper
https://arxiv.org/abs/2305.14314LLaMA Research
https://ai.meta.com/llama/Anthropic Constitutional AI Research
https://www.anthropic.com/research/constitutional-ai-harmlessness-from-ai-feedbackOpenAI RLHF Overview
https://openai.com/research/learning-from-human-preferencesNIST AI Risk Management Framework
https://www.nist.gov/itl/ai-risk-management-frameworkOWASP Top 10 for LLM Applications
https://owasp.org/www-project-top-10-for-large-language-model-applications/Hugging Face PEFT Documentation
https://huggingface.co/docs/peft/indexTransformer Architecture Paper
https://arxiv.org/abs/1706.03762Meditron Research
https://arxiv.org/abs/2311.16079
Enjoyed this article? Share it: